AI Workshop
Marián Boďa | 6. marca 2026
Ciele workshopu
- Iskra AI mindsetu
- Nebáť sa experimentovať
- Poznať riziká a vedieť sa im vyhnúť
- Vedieť aké nástroje existujú a kedy ich použiť
- Dohodnúť sa na ďalších krokoch pre AI v R-SYS
Rýchly level check
Zdvihnite ruku:
- Kto používa AI neustále? (je to súčasť každej úlohy)
- Kto niekoľkokrát denne?
- Kto občas / keď si spomenie?
- Kto zatiaľ skoro vôbec?
Čo dnes budeme robiť
| Čas | Blok |
|---|---|
| 9:00–10:00 | Úvod + novinky v AI |
| 10:00–10:30 | R-SYS AI Review |
| 10:30–10:40 | Prestávka |
| 10:40–11:10 | R-SYS AI Review — pokračovanie |
| 11:10–12:00 | Claude + bezpečnosť |
| 12:00–13:00 | Obed |
| 13:00–14:00 | Cvičenia |
| 14:10–15:10 | Cvičenia |
| 15:20–16:30 | Pokročilé techniky + automatizácia |
| 16:30–17:00 | Zhrnutie + akčný plán |
Rýchly refresh základov
Slovník
- AI — Umelá inteligencia
- LLM — Veľký jazykový model; AI na spracovanie textu
- Agent — Autonómny AI proces schopný plánovať a používať nástroje
- Token — Najmenšia jednotka textu (slovo alebo časť slova)
- Context window — „Pamäť" modelu v rámci jednej session
- Prompt — Zadanie alebo otázka pre AI
- AI slop — Nekvalitný AI generovaný obsah
Čo je Token?


Čo je LLM?

Čo je Agent?

Stav AI: September 2025 → Marec 2026
Najintenzívnejších 6 mesiacov v histórii AI
Kadencia vydávania modelov
Tradičný cyklus "jeden model za rok" je mŕtvy.
| Lab | Modely od septembra 2025 |
|---|---|
| OpenAI | 5.1, 5.2, 5.3, 5.4 |
| Anthropic | Sonnet 4.5, Haiku 4.5, Opus 4.5, Opus 4.6, Sonnet 4.6 |
| Gemini 3 Pro, 3 Flash, 3.1 Pro | |
| xAI | Grok 4, Grok 4 Heavy, Grok 4.1 |
Benchmarky: Všetci na vrchu
| Benchmark | GPT-5.2 | Claude S4.6 | Gemini 3.1 Pro | Grok 4 |
|---|---|---|---|---|
| SWE-bench (kód) | 80.0% | 79.6% | 80.6% | 72–75% |
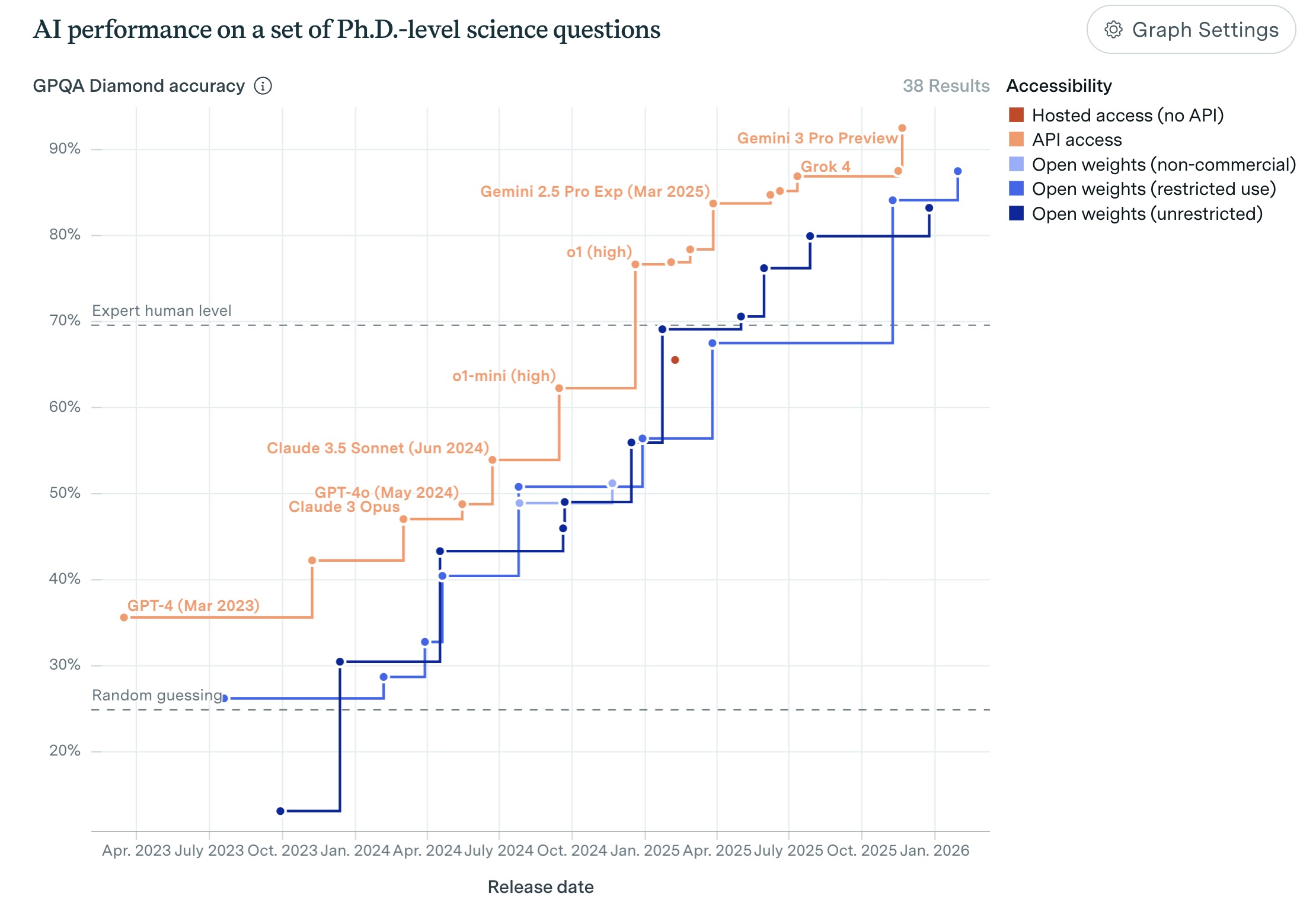
| GPQA (veda) | ~88% | 83.4% | 94.3% | 87–88% |
| ARC-AGI-2 (rozum) | — | 58.3% | 77.1% | 15.9% |
| HLE (expert) | 34.5% | — | 44.4% | 38.6% |
Rozdiel medzi top modelmi: 1–2 percentuálne body
llm-stats.com/leaderboards/llm-leaderboard
Ceny padajú, kvalita rastie
Cena za 1M tokenov (výstup)
─────────────────────────────
Opus 4.1 (mar 2025): $75.00
Opus 4.6 (feb 2026): $25.00 ← -67%
Gemini 3 Flash: $3.00
Gemini 3 Flash Lite: $0.50
DeepSeek API: $0.27 ← reasoning
1M-tokenové kontextové okno je teraz štandard.
Open-source dohnal komerciu
| Model | Parametre | Licencia | Kde beží |
|---|---|---|---|
| DeepSeek V3.2 | 685B | MIT | Cloud / HW |
| Qwen 3.5 | 397B | Apache 2.0 | Mac 128GB RAM |
| Mistral Large 3 | 675B MoE | Apache 2.0 | Cloud |
| GPT-OSS-20B | 20B | Apache 2.0 | 16GB RAM |
Tréning DeepSeek-R1: $5.9 milióna
Reasoning je teraz súčasť modelu
2026 Q1: Reasoning je vstavaný. Nastavíte "effort" parameter.
reasoning_effort: low → rýchle, lacné
reasoning_effort: medium → dobrý kompromis
reasoning_effort: high → max kvalita
reasoning_effort: max → +10–30% presnosť, 5-100x cena
Claude 4.6 → "Adaptive Thinking" — model si sám vyberie hĺbku.
MCP vyhral vojnu štandardov
- November 2024: Anthropic predstavil MCP
- December 2025: darovaný Linux Foundation
- Marec 2026: 97M stiahnutí/mesiac
Podporujú: Claude, ChatGPT, Cursor, Gemini, VS Code, Copilot
krátko na to: "MCP je mŕtve, nech žijú skills a CLI"
CLAUDE.md — pred a po
- September: Zachyťte dôležité veci do CLAUDE.md
- Dnes: "CLAUDE.md kontraproduktívne"
R-SYS AI Review
Teraz vy. Čo používate? Čo funguje? Čo nie?
Context Engineering + Bezpečnosť
Ako nakresliť sovu
Takto väčšina ľudí zadáva úlohy AI.
Málo kontextu
"Napíš test case pre login" → generický výstup
Priveľa kontextu
1000-riadkový prompt so všetkým čo vás napadne → AI sa stratí, protichodné inštrukcie, horší výsledok
Zlý kontext
Irelevantné informácie, zastaralé požiadavky → AI ide zlým smerom s veľkou istotou
Priveľa a zlý kontext sú HORŠIE ako málo kontextu.
Context Engineering
Nie "prompt engineering" — to je len otázka
Context = všetko čo AI vie, keď začne pracovať:
- Systémové inštrukcie (kto ste, čo chcete)
- Príklady (few-shot) — ukážte čo chcete
- Obmedzenia a formát výstupu
- Prístup k dátam (tools, MCP)
- CLAUDE.md / pravidlá projektu
Bad → Good → Great
Bad
"Napíš test case pre login"
Good
"Si QA inžinier. Napíš test cases pre login. Zahrň happy path, nesprávne heslo, expirovanú session."
Great
<switch to plan mode> "Napíš test case pre login"
Bezpečnosť
Čo AI vidí, AI môže poslať
- Pozor na citlivé dáta
- Firemný kód, heslá, API kľúče, osobné údaje
- Ideálne izolovať tajomstvá
- Claude Pro — dáta sa nepoužívajú na tréning (ale sú na serveroch Anthropic)
Bezpečnosť
Prompt injection
- Útočník vloží inštrukcie do dát, ktoré AI spracováva
- AI ich vykoná, pretože nevie rozlíšiť dáta od inštrukcií
- Relevantné pre každého kto AI integruje do produktov
Agent s prístupom = agent s mocou
Čím viac nástrojov agent má, tým väčšie riziko:
- WhatsApp/Email — agent pošle správu vašim kontaktom
- Súborový systém — prečíta/prepíše súbory, ktoré nemá
- Databáza — zmaže alebo zmení produkčné dáta
- Git — pushne kód bez review
Agent s prístupom = agent s mocou
Agent nemusí byť zlomyseľný. Stačí zlý prompt, hallucinácia, alebo prompt injection — a koná vo vašom mene.
Pravidlo: Dávajte agentom len tie prístupy, ktoré naozaj potrebujú.
Nástroje
Claude Desktop / Web
- Deep Research — hĺbková analýza témy, stovky zdrojov
- Projects — kontext zdieľaný naprieč konverzáciami
- Artefacts — interaktívne výstupy (kód, dokumenty, grafy)
- Plugins — napojenie na externé služby
- Skills — extra schopnosti
Alternatívy
ChatGPT / Codex
- ChatGPT — univerzálny, dobrý na konverzáciu a generovanie
- Codex — OpenAI agent pre kód, beží na cloud VM
Gemini
- Štedrý balíček zadarmo, 1M tokenov kontext
- Výborný na YouTube sumáre — rozumie celému videu
Ďalšie nástroje
Hlas
- ElevenLabs — text-to-speech, klonovanie hlasu, dabbing
Automatizácia
- n8n — open-source workflow automatizácia, self-hosted
- Make (Integromat) — vizuálne prepojenie služieb, cloud
Zhrnutie + Akčný plán
Akčný plán
Napíšte si JEDNU vec:
"Keď ____, použijem ____ na ____."
Príklady:
- "Keď budem písať testy, použijem Claude na edge cases"
- "Keď budem prekladať, použijem Claude namiesto Google Translate"
- "Keď budem robiť review, použijem Claude Code"
- "Keď budem písať dokumentáciu, použijem Claude na prvý draft"
Ďalšie kroky pre R-SYS
- Kto bude AI champion v tíme?
- Aké úlohy sa oplatí automatizovať ako prvé?
- Interné zdieľanie — čo komu funguje?
- Workshop 2: 13. marca — developeri
Ďakujem!
marianboda@gmail.com | 0949 195 091